Cos’è Ontopia? E’ una famiglia di ontologie e di vocabolari controllati pensata per il mondo della pubbliche amministrazioni. Sì, ma cos’è un’ontologia? Un’ontologia è la concettualizzazione di una realtà di interesse ottenuta mediante la definizione formale di un dominio specifico attraverso un linguaggio di modellizzazione.
Seee, vabbè, buonanotte. Giovà, me so perso… concettualizzazione, modellizzazione, linguaggio??? Ma che vor dì???

Ok, cominciamo dall’inizio e con una storia.
Lucy accompagna la madre dal dottore che, dopo averla visitata, le prescrive delle sedute di fisioterapia. Lucy chiede al suo smartphone di trovare la lista dei dottori coperti dall’assicurazione della madre col più alto numero di feedback positivi secondo il servizio sanitario nazionale e che non siano lontani più di 20 chilometri dalla casa della madre. Lo smartphone di Lucy recupera l’agenda dei dottori più vicini e crea dei potenziali appuntamenti compatibili sia con l’agenda personale di Lucy sia con l’agenda del fratello Pete, con cui Lucy dovrà organizzarsi per accompagnare la madre alle sedute. Immediatamente Pete riceve sul suo smartphone l’elenco dei potenziali appuntamenti ma su alcune date non è d’accordo; Pete modifica quindi alcune date e riduce la distanza massima dei dottori da cercare a 15 chilometri. Queste restrizioni portano alla generazione di un nuovo calendario di potenziali appuntamenti. Lucy riceve le nuove date generate e le vanno bene. In questo modo le sedute di fisioterapia vengono automaticamente prenotate nell’agenda del dottore selezionato.
Questo racconto è tratto dal famoso articolo del Scientific American del 2001, in cui Tim Berners-Lee, creatore del Web e del Semantic Web, descrive la sua idea di Web, un ambiente in cui i programmi sono in grado di comprendere il significato delle parole e di prendere decisioni in modo autonomo.
Il Web così come lo conosciamo è costituito da pagine esplorabili all’interno di applicazioni chiamate browser, utilizzate dagli utenti per navigare la rete. I browser hanno il compito di rappresentare le pagine favorendo lo scambio di informazioni tra umani. Gli stessi browser, però, non sanno nulla degli argomenti trattati nella pagine, non sono in grado di comprendere il significato delle informazioni rappresentate né sono dotati di intelligenza per improvvisare ragionamenti logici in piena autonomia. Possiamo dire quindi che le informazioni rappresentate nelle pagine Web non favoriscono lo scambio tra programmi.
Ma come possono diventare intelligenti le macchine? Come possono capire il significato delle informazioni presenti nel Web?
Per rendere il Web intelligente è necessario creare un ambiente in cui a tutte le “cose” esistenti vengono associate informazioni e dati (metadati) in grado di specificarne il contesto semantico in un formato adatto all’interpretazione e all’elaborazione automatica. Le macchine non hanno l’abilità di capire il significato delle parole, a meno che non si creino le condizioni affinché possano comprendere e questo deve essere fatto in un linguaggio a loro comprensibile. Questo nuovo tipo di ambiente prende il nome di Web Semantico e, non solo consente lo scambio di informazioni tra programmi ma aumenta indirettamente ed esponenzialmente anche la quantità di informazioni che possono utilizzare gli esseri umani.
Uno specifico ambito di conoscenza può essere rappresentato in modo comprensibile dalle macchine utilizzando gli strumenti del Web Semantico, codificando cioè le informazioni tramite i concetti del dominio (classi, proprietà, e restrizioni). Il risultato di queste concettualizzazioni viene definito comunemente ontologia.
Non è scopo di questo post entrare nel dettaglio sugli strumenti tecnici del Web Semantico. Per maggiori informazioni potete fare riferimento alla serie di post presenti in questo blog: [1,2,3,4,5,6,7,8,9,10]
Perchè Ontopia
Per spiegare le motivazioni che hanno dato origine al progetto Ontopia prendiamo ad esempio il dominio dei servizi pubblici delle PA.
Alcuni di essi, anche se non tantissimi, sono disponibili online. Nonostante questo, però, i servizi pubblici potrebbero essere più efficienti se non esistessero barriere tra i servizi stessi, i sistemi IT e i dati. Uno dei più grandi problemi delle PA avviene quando i dati dei sistemi IT non possono essere scambiati tra sistemi diversi perché descritti in modo incompatibile; ciò avviene quando abbiamo problemi di semantica. Per superare questo ostacolo è necessario creare delle connessioni significative tra dati e per fare questo è necessario seguire standard aperti e condivisi. Questo limite non deve riguardare però solo il territorio nazionale; il patrimonio informativo delle PA dovrebbe essere riutilizzato e condiviso tra i tutti gli stati d’Europa e collegato insieme ad altre pubbliche amministrazioni, aziende e cittadini in un unico mercato digitale europeo.
Anche la Commissione Europea, nel documento quadro European Interoperability Framework, che mira a potenziare l’interoperabilità dei servizi pubblici nell’Unione Europea, afferma infatti che “l’agenda digitale può decollare solo se è garantita un’interoperabilità basata su standard e piattaforme aperte”.
Purtroppo, però, nelle PA italiane si riscontrano ancora le seguenti criticità:
- mancanza di standard condivisi in uso alle applicazioni software che gestiscono l’attività amministrativa;
- ogni applicativo, il più delle volte proprietario, gestisce i dati della PA secondo logiche che non supportano nativamente l’interoperabilità semantica, cioè lo stesso concetto di un dominio condiviso tra diverse PA viene rappresentato in modo diverso a seconda dell’applicativo che lo gestisce. A questo costo si aggiunge spesso anche quello causato dal lock-in del fornitore, cioè quando le PA, per la difficoltà a migrare verso sistemi IT più moderni offerti da aziende terze, rimangono imprigionate allo stesso fornitore ICT;
- mancanza di una regia unica nazionale che proponga e imponga dall’alto l’utilizzo di una solida e stabile architettura dell’informazione dei dati pubblici e che obblighi i fornitori ICT a rilasciare i propri applicativi secondo tali standard.
In realtà sull’ultimo punto è necessario aggiungere qualcosa, ma procediamo per passi.
Dal punto di vista normativo l’Italia da anni insiste e incentiva l’adozione di standard condivisi come dimostrano i seguenti riferimenti:
- Art. 20 - Comunità intelligenti - della legge n. 221 del 17 dicembre 2012, recante misure urgenti per la crescita del Paese:
- L’Agenzia per l’Italia Digitale (AGID) definisce strategie e obiettivi, coordina il processo di attuazione e predispone gli strumenti tecnologici ed economici per il progresso delle comunità intelligenti. A tal fine l’Agenzia: […] c) emana le linee guida recanti definizione di standard tecnici, compresa la determinazione delle ontologie dei servizi e dei dati delle comunità intelligenti;
- Linee guida per la valorizzazione del patrimonio informativo della Pubblica Amministrazione - AGID:
- Il documento,[…], approfondisce l’uso di un insieme di standard di base e di ontologie e vocabolari specifici per categorie trasversali e verticali di dati delle pubbliche amministrazioni, al fine di guidare nell’effettiva implementazione dei modelli proposti, i.e., dei dati e dei metadati, e operativo.
- Vocabolari controllati e modelli di dati - Capitolo 4 del Piano Triennale ICT 2017/19
Con queste premesse normative, da diversi anni l’AGID, Agenzia per l’Italia Digitale, in collaborazione con il Team per la Trasformazione Digitale, ha quindi intrapreso l’ardua sfida di standardizzare il patrimonio informativo della pubblica amministrazione, creando una famiglia di modelli di dati, cioè ontologie, con lo scopo di identificare e definire schemi condivisi per dati trasversali e non, ai diversi domini applicativi delle PA. Contemporaneamente l’AGID ha sviluppato dei vocabolari controllati, ottenuti armonizzando e standardizzando tassonomie, codici e nomenclature, da utilizzare come categorizzazioni nelle ontologie e nelle basi di dati pubbliche.
Questa iniziativa dell’AGID prende il nome di Ontopia e rappresenta, a mio avviso, uno dei più interessanti e ambiziosi progetti di AGID, perché costituisce la base e le fondamenta su cui, in maniera imprescindibile, dovrà essere fondata la pubblica amministrazione del futuro e da cui si dovrà partire per riuscire a dare una nuova immagine alle PA. Una PA che sia moderna e innovativa, trasparente e aperta, i cui dati siano semanticamente interoperabili, per facilitare lo sviluppo di nuovi sistemi informativi, per agevolare lo scambio di dati, per abilitare l’integrazione tra dati provenienti da fonti diverse.
Standardizzare l’architettura del patrimonio informativo delle pubbliche amministrazioni significa definire un linguaggio comune per l’interscambio dei dati, significa creare un ambiente in cui poter interrogare quello che viene chiamato il grafo della conoscenza della pubblica amministrazione italiana o Knowledge Graph. E tutto questo, in Ontopia, viene fatto sfruttando le potenzialità del Web Semantico.
Il progetto Ontopia è sviluppato con il supporto del laboratorio di tecnologie semantiche dell’Istituto di Scienze e Tecnologie della Cognizione (ISTC) del CNR e in collaborazione con diversi enti centrali e locali; è rilasciato con licenza aperta ed è allineata ai cosiddetti Core Vocabulary del programma ISA2 della Commissione Europea.
I principi cardine su cui si basa Ontopia sono:
- il processo di creazione del progetto Ontopia si è avvalso di una metodologia iterativa, incrementale e collaborativa di modellazione delle ontologie basata su pattern, cioè su soluzioni di modellazione per problemi che ricorrono con frequenza. Questa pratica metodologica prende il nome di Agile eXtreme Design ed è stata associata all’uso dei design pattern per le ontologie;
- il progetto ha respiro europeo e la lingua di riferimento è l’inglese; le etichette degli elementi dell’ontologia e dei vocabolari controllati sono in inglese, in italiano e a volte in tedesco;
- ogni elemento dell’ontologia è identificato univocamente da una URI, resa persistente dal servizio w3id.org;
- le ontologie e i vocabolari controllati sono disponibili in varie serializzazioni: rdf/xml, rdf/turtle, json-ld;
- è possibile navigare tra le ontologie e i vocabolari controllati tramite interfaccia Web;
- è possibile fare interrogazioni tramite un endpoint SPARQL disponibile al seguente link;
- il progetto Ontopia riusa ontologie in modo indiretto ed effettua gli allineamenti in file separati.
L’approccio tecnico di modellazione di Ontopia è rappresentato nella seguente figura:
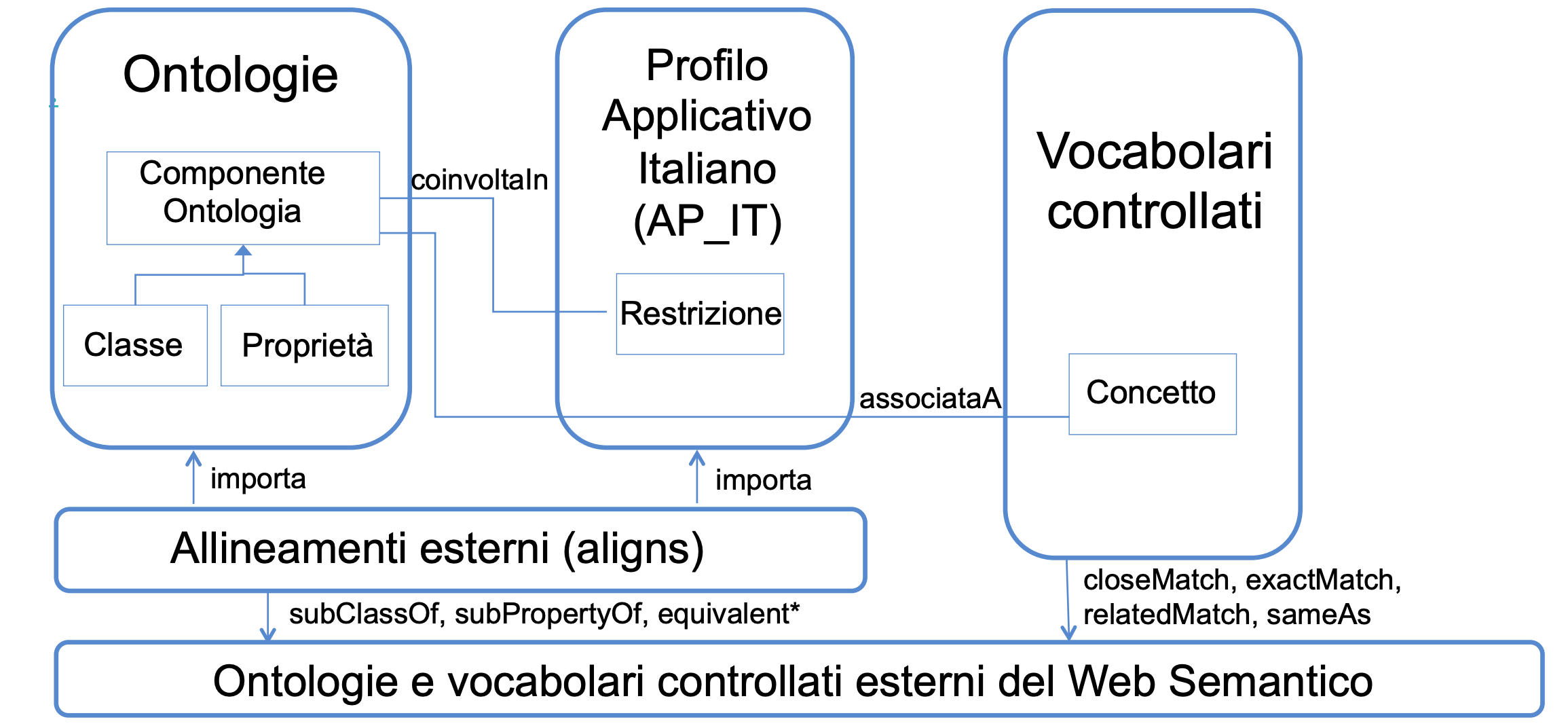
Tipicamente, nel creare un’ontologia, i componenti più importanti sono le classi e le proprietà. Le ontologie del progetto Ontopia fanno riferimento a profili applicativi nazionali, cioè sono state sviluppate tenendo in considerazione, da un lato l’esistenza di eventuali modelli di dati europei e/o internazionali, in modo da non dover reinventare la ruota, dall’altro declinando le ontologie su profili di conformità alla realtà italiana, cioè inserendo vincoli restrittivi in grado di descrivere un dettaglio più rispondente al mondo delle PA nazionali grazie ai quali è possibile migliorare e mantenere una più alta qualità dei dati descritti.
Inoltre, i concetti delle ontologie sono collegati esternamente ad un vocabolario controllato.
Un esempio fra tutti. Nell’ontologia delle Strutture Ricettive (ACCO), la classe Accomodation, che è la classe principale che definisce la struttura ricettiva, ha la proprietà hasAccommodationTypology il cui oggetto deve essere un concetto di tipo AccommodationTypology. Le istanze di questa classe sono concetti del vocabolario controllato https://w3id.org/italia/controlled-vocabulary/classifications-for-accommodation-facilities/accommodation-typology
definito esternamente all’ontologia. Tra queste istanze, che sono concetti definiti formalmente e univocamente tramite URI, troviamo ad esempio Motel, Agriturismo, Ostello per la gioventù, etc.
Le ontologie di Ontopia non sono autoreferenziali e chiuse a se stesse ma riutilizzano ontologie e vocabolari controllati esistenti, e definiscono, in un file esterno, tutti gli allineamenti del caso. Ad esempio, il concetto di Organization viene definito nell’ ontologia Core Organization Vocabulary di Ontopia ma viene anche allineato al concetto Organization dell’ontologia Organization del consorzio W3C. Nel file esterno di allinamento troviamo infatti la definizione covapit:Organization di Ontopia sottoclasse di org:Organization dell’ontologia W3C.
La possibilità di estendere e riusare i concetti delle ontologie ha un impatto molto forte in termini di integrazione dei dati di Ontopia con altri dati esterni, modellati con ontologie direttamente o indirettamente allineate con Ontopia. Allineare ontologie significa costruire ponti tra grafi di conoscenza diversi, supportare e favorire lo scambio di informazioni, abbattere e superare l’approccio a silos solitamente adottato nelle PA italiane.
La seguente figura illustra invece lo stack ontologico del progetto Ontopia.
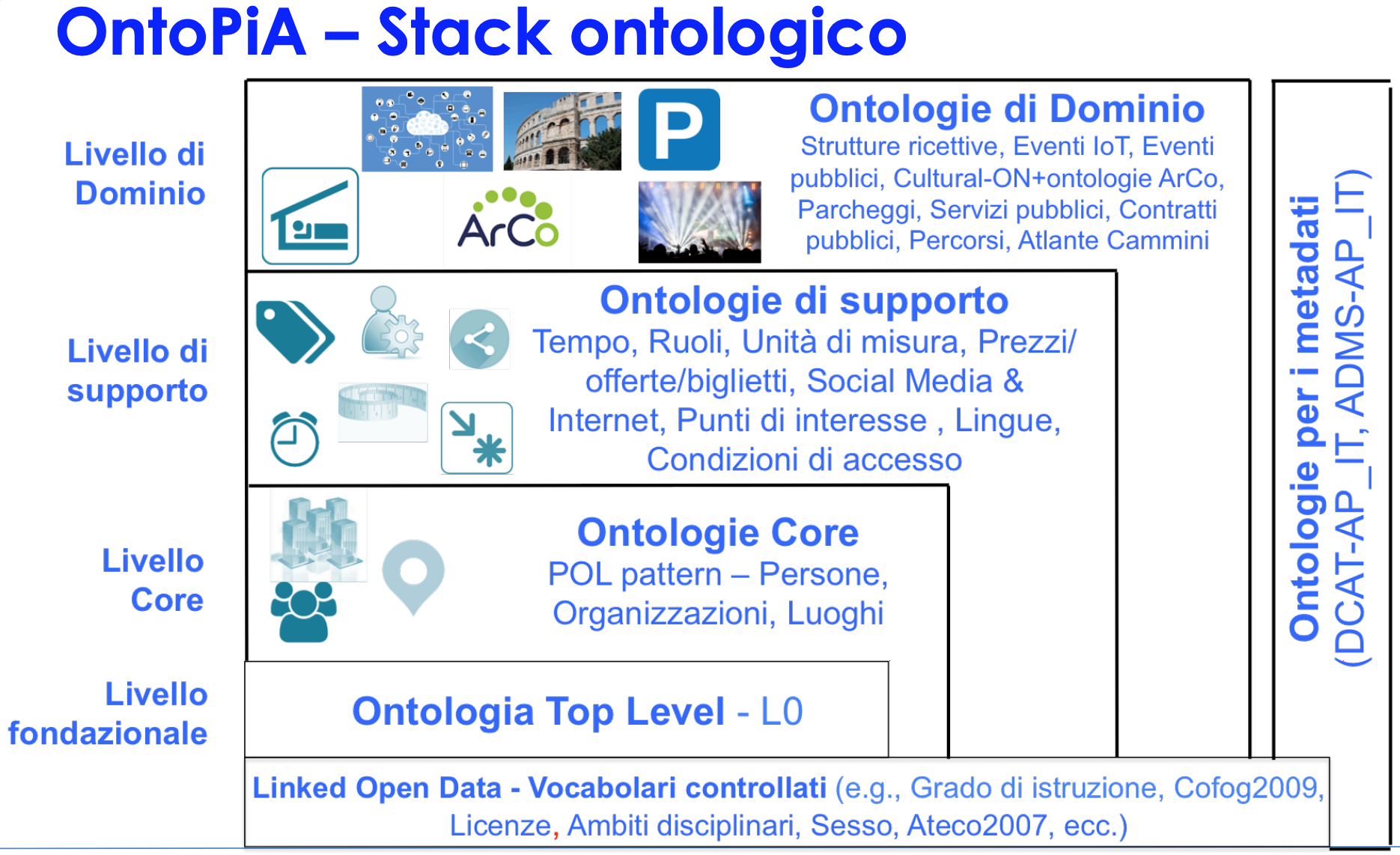
In Ontopia possiamo distinguere diversi livelli di ontologie organizzate a stack, dove le ontologie dei livelli più bassi sono riutilizzate dalle ontologie di livello più alto e mai il contrario. L’appartenenza ad uno specifico livello dipende dalle caratteristiche dell’ontologia stessa e dallo scopo per cui è stata sviluppata.
I livelli di Ontopia sono:
- Livello fondazionale L0 - l’ontologia L0 rappresenta un’ontologia di tipo top level; sono definiti termini molto generali utilizzati in tutte le altre ontologie di Ontopia, ad esempio concetti come Evento, Sistema, Caratteristica, Entità, Location. L’ontologia L0 rappresenta il fulcro del progetto Ontopia e consente a tutte le altre ontologie del progetto di essere collegate tra loro.
- Livello core - le ontologie del livello core sono indipendenti dai concetti dei domini verticali e possono essere usati per descrivere in maniera trasversale concetti di più dataset. Fanno parte di questo livello le ontologie:
- sulle persone, sviluppata in collaborazione con ISTAT;
- sulle organizzazioni, sviluppata a partire dall’indice delle pubbliche amministrazioni IPA;
- sui luoghi, sviluppato con ISTAT e l’agenzia delle Entrate.
- Livello di supporto - le ontologie di questo livello modellano concetti di supporto alle altre ontologie; troviamo concetti relativi al tempo, ai ruoli, alle unità di misura, ai prezzi, ai social media, ai punti di interesse, alle lingue, alle condizioni di accesso, etc.
- Livello di dominio - le ontologie di questo livello modellano concetti relativi a domini specifici. Sono presenti le ontologie relative:
- alle Strutture Ricettive;
- agli Eventi IOT, utilizzata per modellare il traffico in tempo reale;
- agli Eventi pubblici;
- al Mondo della Cultura;
- ai Servizi Pubblici, utilizzata nella piattaforma servizi.gov.it;
- ai Contratti Pubblici, sviluppata insieme ad ANAC, Regione Piemonte e Synapta.
- Vocabolari controllati - tassonomie di termini ricorrenti da utilizzare come istanze di dati per le ontologie di Ontopia e nelle basi di dati pubbliche;
- Ontologie per i metadati: in questa categoria fanno parte le ontologie DCAT-APIT, per la metadatazione dei cataloghi dati e l’ontologia ADMC-APIT, per metadatare le ontologie stesse.
Dove si trova Ontopia?
Ontopia è un progetto aperto, fortemente collaborativo e partecipativo. Tutte le risorse disponibili sono su un repository GitHub in cui è possibile partecipare, sia aprendo o rispondendo a issues, per consigli, suggerimenti, feedback sulle ontologie e i vocabolari controllati, sia inviando, tramite PR, eventuali estensioni, modifiche e/o correzioni degli attuali schemi caricati.
Conclusioni
In questo post ho voluto raccontare, seppur in maniera introduttiva, il progetto Ontopia, una delle iniziative istituzionali più sfidanti degli ultimi anni. Una piattaforma di modelli di dati istituzionale, aperta e creata in modo collaborativo con centri di ricerca (CNR Roma), con pubbliche amministrazioni (ISTAT, MIBAC, Regione Piemonte, ANAC, Comune Palermo e Udine, Provincia Autonoma di Trento) e soprattutto con tutte le persone che vogliono contribuire al progetto, interagendo con GitHub.
Una piccola nota personale.
Circa 10 anni fa, durante il mio dottorato di ricerca, mi appassionai di Semantic Web e creai delle ontologie per la rappresentazione sia del mondo universitario italiano (SWIUP) sia delle statistiche dell’anagrafe studenti (LOIUS). In quella attività di ricerca descrissi in modo formale un pezzetto di pubblica amministrazione, nello specifico quella del Ministero dell’Istruzione, Università e Ricerca (MIUR). Quell’esperienza mi insegnò molte cose sul mondo del Semantic Web e dei Linked Data; appresi come definire modelli per la rappresentazione della conoscenza e come favorire l’interoperabilità semantica in contesti molto particolari come il mondo delle PA. Tuttavia quel lavoro morì subito dopo la consegna della tesi e da allora sono trascorsi quasi 10 anni.
In Ontopia, in quest’ambizioso progetto istituzionale che si impone in maniera così massiccia e trasversale sui domini applicativi delle PA, rivedo la concretizzazione reale e consistente di ciò che in una piccolissima parte avevo cercato di fare anch’io 10 anni fa, cercare cioè di rendere la PA più moderna; sono fortemente convinto che Ontopia sia la rotta giusta da seguire, supportare e incoraggiare, motivo per cui mi sento stimolato, nel mio piccolo, a contribuire al progetto.
Da Ontopia sto imparando molto, sto studiando l’approccio utilizzato per la creazione delle ontologie e dei vocabolari controllati e ho scoperto nuove tecniche di modellazione basate sui design pattern che non conoscevo.
Sto studiando, ho ancora tanto da imparare e sto cercando di dare il mio contributo nei seguenti modi:
- ho suggerito dei vocabolari controllati per il mondo universitario confrontandomi principalmente con Giorgia Lodi, consulente AGID, coordinatrice del progetto Ontopia, nonché esperta di Semantic Web. Sono nati due vocabolari controllati che ho proposto tramite PR su GitHub e che adesso fanno parte di Ontopia;
- con Davide Taibi stiamo cercando di “ontopizzare” l’ontologia OpenARS, modello di dati sviluppato per la rappresentazione dei dati sull’attività parlamentare dell’Assemblea Regionale Siciliana (ARS), che abbiamo presentato l’anno scorso a Palermo in occasione del raduno annuale della comunità Open Data Sicilia;
- ho rispolverato il mio vecchio progetto di modellazione del dominio delle università italiane e ho intenzione di creare una nuova ontologia - integrata con Ontopia - in grado di rappresentare concetti, relazioni e proprietà delle offerte formative e dei manifesti degli studi delle Università italiane;
- infine, non per importanza, sto cercando di portare Ontopia anche all’interno della PA in cui lavoro: ho progettato e implementato una piattaforma prototipo per la gestione della carta dei servizi, rendendola compliant allo standard europeo CPSV-AP nella sua declinazione italiana CPSV-AP_IT (Core Public Service Vocabolary - Application Profile Italy) di Ontopia. Il prototipo è in grado di generare al volo lo schema RDF della carta dei servizi e di renderlo disponibile online per poter consentire in futuro l’harvesting dal portale servizi.gov.it. La piattaforma è inoltre in grado di creare automaticamente i file .RST (reStructuredText) necessari per generare automaticamente la documentazione tramite SPHINX, secondo le linee guida del progetto Docs Italia del Team per la Trasformazione Digitale. Ciò consentirà la pubblicazione automatica della carta dei servizi sul portale nazionale dei documenti pubblici digitali. Infine, la piattaforma è in grado di dialogare con un chatbot Telegram sia per ottenere le informazioni dei servizi pubblici sia per fruire di servizi di geolocalizzazione e indicazioni stradali dei servizi pubblici offline. In futuro spero di poter condividere quest’esperienza di progetto attraverso i canali ufficiali della mia PA.
Da diversi mesi avevo intenzione di scrivere un post sul progetto Ontopia e, complice il lungo ponte di Pasqua, finalmente ho trovato il tempo per farlo. Spero di essere riuscito a trasmettere un po’ di interesse e di entusiasmo a tutte quelle persone che hanno a che fare con il mondo delle PA a vario titolo (amministratori, dirigenti, dipendenti) e che sono chiamate a fare scelte importanti nei propri enti in materia di innovazione e modernizzazione.
Molto di ciò che ho scritto l’ho potuto apprendere da Giorgia Lodi, esperta di tecnologie semantiche, professionista di altissima competenza, che ringrazio.
Per maggiori approfondimenti sul progetto Ontopia sono disponibili le seguenti risorse online, da cui sono stato fortemente ispirato.