In the previous Semantic Web posts [1,2,3,4,5,6,7,8,9,10] I introduced tools, standards and languages to try to overcome the problem to integrate and reuse information between different applications. In this post I am going to describe a different way to present and share data on the Web, that, in recent years, played an important role in the development of Semantic Web applications concretely showing the benefits of semantic technologies. In 2006, the father of the HTML language and of the Semantic Web, Tim Berners–Lee, proposed a very simple way to publish structured data on the Web. The Linked Data era began!
From the technological point of view, Tim Berners–Lee invented nothing new but simply defined some rules for publication and interlinking RDF data on the Web, thus stirring up a very high interest by the scientific and business community around the world.
Linked Data Rules
The Linked Data principles recommend to:
- Use URIs as names for things;
- Use HTTP URIs so that people can look up those names;
- When someone looks up a URI, provide useful information, using the standards;
- Include links to other URIs, so that they can discover more things.
The basic principle of Linked Data is that data value increases if it is interlinked with other data. Structured data should be published using semantic languages and data would be linked with external sources through typed RDF links. The current Web is similar to a large filesystem where documents are scattered without information on the content meaning, and connected using untyped meaningless links. Instead, the Web of Data can be considered as a huge global database published on the Web, available to all interested people that may query, integrate, reuse, export data to develop applications on top of it. Increasing RDF links between resources belonging to different datasources means allowing search engines to carry out flexible queries similar to those provided by a relational database. Before talking about the four Linked Data principles, we define some terms that will help us go forward in this post.
As known, each URL is a particular type of URI, starting from http: string, defining the path to find a specific resource on the Web. The http: scheme of each URL also specifies the protocol used to access on the net through browsers; each URL address is then called deferencable because it is relative to a resource on the Web retrievable through a well–known mechanism. Instead, putting in our browser URIs with tag: or urn: schemes, we are not able to find any resources because the relative protocols do not specify how to find items. In this case we know the URIs as not deferencable.
The first Linked Data rule states to use URIs as names for things but not only things related to Web such as images, documents, video and so forth, but also for real–world objects like people, hotels, cars and even abstract ideas and non–existing things.
The second rule proposes to use HTTP URIs so that people can look up those names. The reason of this is very simple. The http:// scheme is the only URI scheme that is widely supported in today’s tools and infrastructure. All others require extra effort for passing proxies and firewall layers, for resolver Web services and so on; then, the HTTP protocol can be seen as a universal door to access all resources URIs.
The third Linked Data rule states that when someone looks up a URI, the server would always provide useful information, using the standards. But, given a specific URI, how can we find out what it identifies? Before answering this question we have to classify the resources in two types:
- Information Resources;
- Non-Information Resources.
Information resources are identified by directly deferencable URI, and the result of the request is sent to the browser immediately. When a user requires information resources, the server Web generates a new representation of that resource returning an HTTP response code 200 OK.
We can imagine an information resource as all that can be trasmitted electronically and can be viewed in a browser.
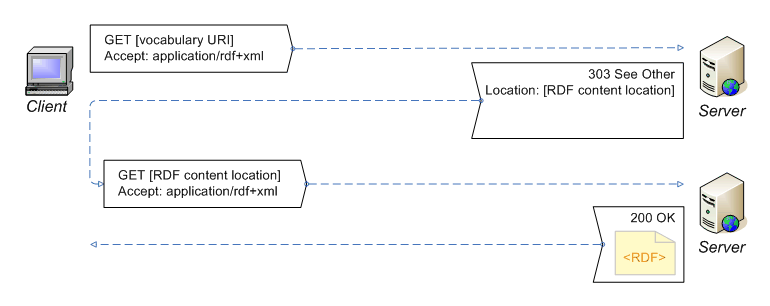
All URIs not directly deferencable are called instead non–information resources. Browsers can only display information resources; therefore, to provide a representation of non–information resources you perform a double step trick. When a user wants to find a non–information resource the Web server redirects to an information resource URI through the HTTP response code 303 See Other. Then, the client performs a new request deferencing the just arrived information resource, finally obtaining a representation of the non–information resource.
So far we have explained how all information resources types can be deferenced using URIs. But, how does the Web server know which information resource has to be returned for a non–information URI request?
The answer is very simple and is related to the HTTP protocol;
in fact, in the HTTP Accept header of the HTTP client request, we can specify the MIME type of the representation type we want.
The Web server reads the requests and starts the content negotiation mechanism to give back the right information resource URI related with the specified representation. Then, if a user requires a non–information resource URI and wants to display it in a normal browser, the client will send in the HTTP Header the attribute Accept: text/html, while for example, if we want to see the resource in an RDF browser, the attribute will be Accept: application/rdf+xml. Therefore, the server will return the related information resource URI that the client will be able to deference displaying the information needed. The following figure shows the content negotiation mechanism.
Dereferenceable URIs can be constructed using two approaches preserving the implicit identity function.
-
Hash approach. In this case the URI is splitted into two parts separated by a hash symbol
#. This type of URI cannot be directly deferencable so we can use it to identify non–informative resources without creating ambiguity because the HTTP protocol, before sending the request to the server, strips off the string after the hash symbol, to retrieve the information resource representation containing the non–resource information description. For example, using this approach to identify the poet Dante Alighieri, the URI could be:http://example.org/poets.rdf#dalighieri. In the content negotiation mechanism, the part after the hash symbol will be removed and the server will return thehttp://example.org/poets.rdfURL within which we will find information about thedalighieriresource in RDF format. -
Slash approach. In this case the non information resource is identified by the string following the last slash symbol
/, and to deference this type of URI, as seen above, the303 - See Othernegotiation mechanism is adopted in order to find the right resource representation. For example, using this approach to identify the person Dante Alighieri, the URI could be:http://example.org/dalighieri. This resource does not exist in the server, then it sends a303redirect to client saying that information about that resource can be found in thehttp://example.org/poets.rdffile within which we will find information about thedalighieriresource in RDF format.
The semantic languages allow to exposes on the Web a large amount of data, and choosing the right URI approach can be fundamental to ensure a good performance of the system. Imagine a large single RDF file published on the Web containing millions of URIs, and let us use the hash approach. When a client wants to retrieve a single resource inside the file, although the resource would be at the top of the file, the server has to return the whole heavy file to find the related URI resource. This can be a bottleneck for the functioning of the system; so, depending on dataset size, we can adopt different strategies combining slash or hash approaches for deferencing URIs, to ensure the better performance to client requests.
Linked Open Data
The fourth and last Linked Data rule states to include links to other URIs in order to discover more things. This principle represents one of the most important rules because by adding RDF links to resources especially belonging to different datasets, we increase the amount of information available on the Web for those resources. Publishing data on the Web using the RDF data model following linked data rules means that clients can look up every URI in a huge graph to retrieve additional external information coming from different sources, merging and exploring datasets, querying and developing applications thus increasing the resource original value.
In 2007, the W3C SWEO group proposed the Linking Open Data (LOD) community project whose goal is to extend the Web with a data commons by publishing various open data sets as RDF on the Web and by setting RDF links between data items from different data sources (link)
In this project, some people embraced the Tim Berners–Lee rules and started to publish open data on the Web making interlinked datasets available.
The open data ideals state that data must be freely reusable by everyone without paying royalties. The LOD community aims to convert all open datasets available on the Web in RDF format to expose them in a structured way, in order to finally allow the free reuse by all, especially by machines that use the potentiality of semantic technologies. The first LOD interlinked datasets were:
- DBpedia: a dataset containing extracted data from Wikipedia; the DBpedia data set currently provides information about 4.58 million things (English version), including 1,445,000 persons, 735,000 places, 411,000 creative works (including 123,000 music albums, 87,000 films and 19,000 videogames), 241,000 organizations (including 58,000 companies and 49,000 educational institutions), 251,000 species and 6,000 diseases. It provides localized versions in 125 languages. Altogether, the DBpedia data set consists of (more than) 3 billion RDF triples (2014 statistics);
- DBLP Bibliography: provides bibliographic information about scientific papers; it contains about 800,000 articles, 400,000 authors, and approximately 15 million triples;
- GeoNames: provides RDF descriptions of geographical features worldwide.
- Revyu: a Review service that consumes and publishes Linked Data, primarily from DBpedia.
- FOAF: a dataset describing persons, their properties and relationships.
From 2007, many projects, communities and developers contributed to increase the number of interlinked dataset inside the LOD cloud diagram. Currently, the LOD project is composed by 1224 data sets encoding more than 31 billion RDF triples, which are interlinked by around 504 million RDF links (2014). The Linking Open Data diagram can be seen in the following figure:
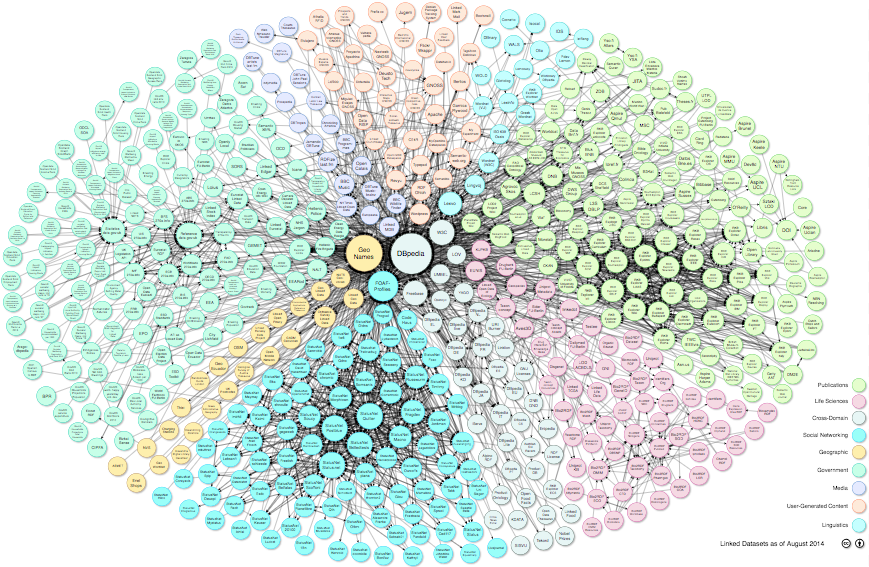
Starting from LOD RDF structured data, we can develop very interesting semantic applications such as browsers, user interfaces, search engine crawlers and reasoning engines. Everybody can contribute to increase the LOD diagram, converting open data to RDF and making it available as linked data and/or SPARQL endpoint on the Web. Thus, linked data paradigm is a way of publishing data on the Web; furthermore, due to semantic Web languages, it encourages reuse, reduces redundancy, and at the same time, maximizes the semantic interoperability between applications.
That’s all folks! Stay tuned!