Tutto ebbe inizio un giorno quando, di buon mattino, in un vecchio baule antico della mia soffitta, ritrovai un vecchio manoscritto di racconti intitolato “Digital Fabulas”, la cui prima pagina recitava:
Questa è la storia di Ioan Pairot, squattrinato maniscalco siciliano, che ebbe la cattiva sorte di vivere secoli or sono alla corte di un potente signorotto palermitano.
Il primo dei racconti iniziava così:
Galeotta fu la telefonata col conte Andreas de los Bash, nobile discendente della casata dei Borrusi, di origine borbonica, insediatasi a Palermo all’inizio del XIX secolo lamentante di non trovare sul situs Webus della Protezione Civilis dell’isola Trinacria notitia circa lo tempo previstus del giorno appresso in forma tal da essere riusata in posti altri da quel situs poco apertus. Maniscalco scapestrato qual ero, nulla potei replicare all’illustre conte, ma il pensier turbò quella mia notte insonne e mi accompagnò fin al mattino. E infin cedetti per lo sfinimento, per appagar del conte il desiderio e ritornar a dormir la notte, quieto e libero da pensier molesti a oltranza.
Per una migliore comprensione del racconto d’ora in avanti tradurrò la storia in lingua moderna.
Dal diario di Ioan Pairot
[…] Il conte Andreas mi informò che la Protezione Civile siciliana pubblicava quotidinamente, sul proprio situs ipertestuales (oggi lo chiameremmo sito o pagina Web), il dispaccio delle allerte dei rischi idrogeologici (oggi lo chiameremmo report o bollettino) dell’intera regione in un formato file chiamato OCD (oggi lo chiameremmo PDF). Tale formato, purtroppo, impediva la possibilità di riusare le preziose informazioni del bollettino in contesti diversi da quello originale e il conte, desideroso di manipolare quei dati, mi intimò di trovare una soluzione al problema.
Conoscendo la sua ira funesta la notte non chiusi occhio ma, alle prime luci dell’alba, un lampo di luce mi guizzò in mente ed…Eureka… trovai la soluzione.
In questo diario descriverò il dettaglio tecnico.
Ogni giorno la Protezione Civile siciliana pubblicava su questa pagina Web il bollettino giornaliero dei rischi idrogeologici della regione, relativi ad un periodo che andava dalle 16 del giorno di pubblicazione fino alle 24 del giorno successivo.

Nel bollettino apparivano diverse mappe della Sicilia suddivise per zone e per ciascuna di esse era riportato il livello del rischio in base alla seguente scala di colori:

Il bollettino veniva pubblicato in PDF per cui le informazioni rimanevano confinate nel file precludendo la possibilità di riutilizzare gli stessi dati in contesti differenti da quello originale.
Per poter individuare il tipo di approccio da attuare ho analizzato attentamente il report della Protezione Civile ponendo particolare attenzione ai colori delle prime due mappe, relative ai livelli di allerta regionali del giorno di pubblicazione e del successivo. Per poter aprire e riusare i dati ingabbiati nel PDF avevo bisogno di grattare i colori di ogni zona al di fuori del file. Dovevo stabilire un insieme di passi (oggi lo chiameremmo algoritmo) in grado di riconoscere i colori delle mappe, in modo automatico e puntuale, al fine di risalire al colore di ogni singolo elemento grafico (oggi lo chiameremmo pixel) presente in ciascuna zona della mappa.
Vediamo i singoli passi
Sul sito della Protezione Civile era presente una pagina con l’elenco di tutti i bollettini meteo e disponibile al seguente URL
http://www.regione.sicilia.it/presidenza/protezionecivile/pp/archivio_idro.asp
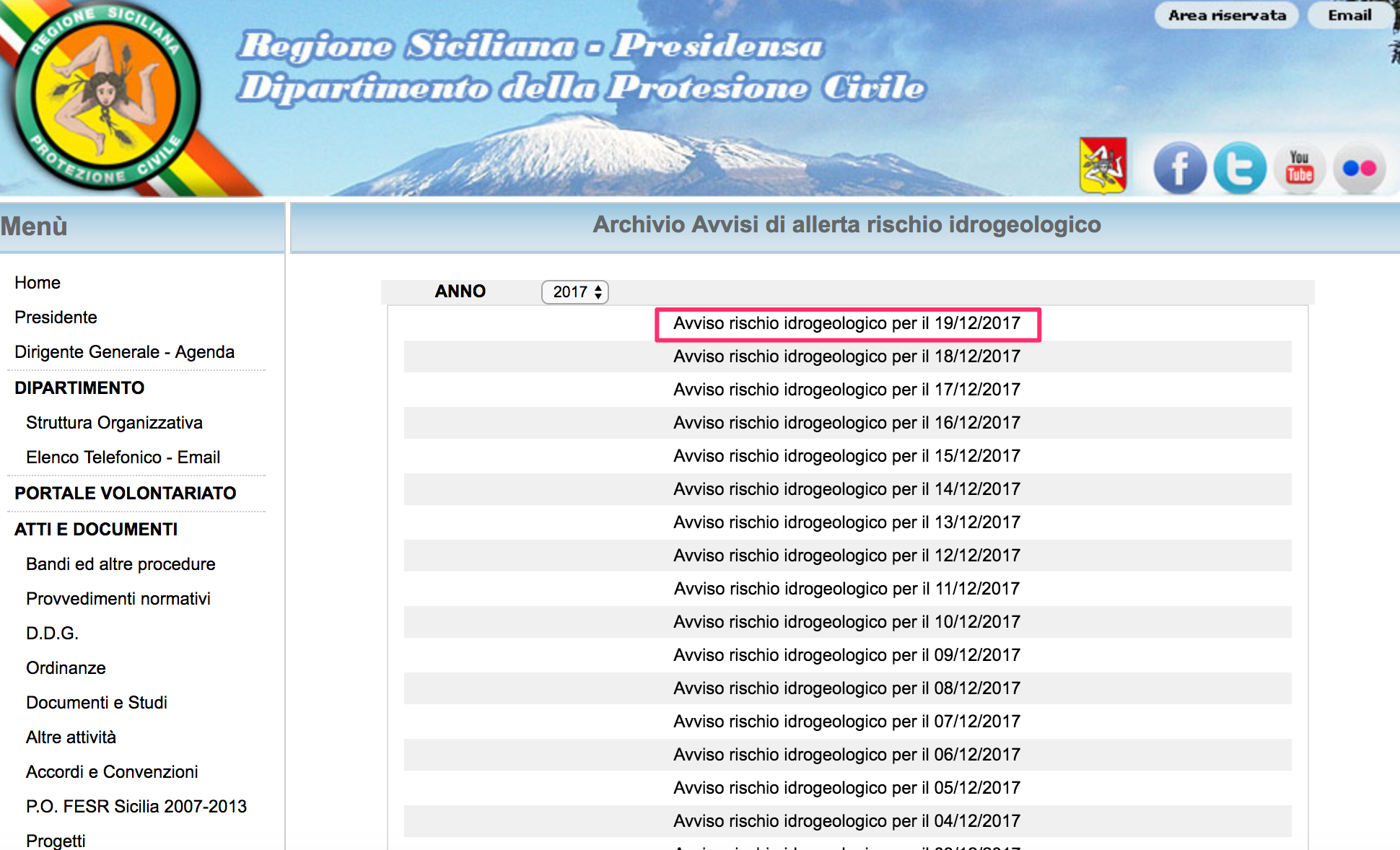
Il primo link dell’elenco rappresentava l’ultimo bollettino pubblicato dalla Protezione Civile. Per estrarre tale link ho utilizzato la libreria BeautifulSoup, ormai lo standard de-facto per lo scraping Web in Angus (oggi lo chiameremmo Python). Di seguito la prima parte del fons (oggi lo chiameremo codice sorgente):
url = 'http://www.regione.sicilia.it/presidenza/protezionecivile/pp/archivio_idro.asp'
r = requests.get(url)
html = r.text
soup = BeautifulSoup(html, 'lxml')
pattern = 'Avviso rischio idrogeologico per il (.*)'
first_row = soup.find('td',{'class':'testo_tabelle_cent'})
text = first_row.text
m = re.match(pattern,text)
if m:
primo_giorno_text = (m.group(1))
primo_giorno = datetime.datetime.strptime(primo_giorno_text, '%d/%m/%Y')
secondo_giorno = primo_giorno + datetime.timedelta(days=+1)
secondo_giorno_text = secondo_giorno.strftime("%d/%m/%Y")
if first_row.a:
link = first_row.a.get('href')
if link:
href = link[3:]
A questo punto href conterrà il link (relativo) del bollettino della Protezione Civile.
WEB_ROOT_URL = 'http://www.regione.sicilia.it/presidenza/protezionecivile/'
full_url = WEB_ROOT_URL + href
file_pdf = 'protezione-civile.pdf'
wget_cmd = 'wget -O ' + file_pdf + ' "' +full_url + '"'
os.system(wget_cmd)
L’algoritmo prosegue con lo scaricamento del file (oggi lo chiameremmo download), attraverso il comando shell wget, invocato da python, grazie al quale otteniamo il trasferimento del PDF in locale sul mio calculator (oggi lo chiameremmo server).
Considerando che le mappe della Sicilia presenti nel report si trovavano sempre in prima pagina e sempre nella stessa posizione, ho iniziato a pensare a come esportare i dati al di fuori del file.

Volendo analizzare i colori delle mappe siciliane, ed essendo queste essenzialmente delle immagini incastonate nel PDF, la prima cosa che mi è venuta in mente è stata quella di convertire la prima pagina del PDF in un’immagine e utilizzare le librerie grafiche disponibili in Python per poter ottenere informazioni sui colori delle specifiche zone.
Attraverso il tool convert di ImageMagick ho convertito quindi la prima pagina del bollettino PDF in formato immagine PNG nel seguente modo:
file_png = 'protezione-civile.png'
file_pdf = 'protezione-civile.pdf'
cmd = 'convert '+ file_pdf + '[0] ' + file_png
os.system(cmd)
Con l’immagine generata ho individuato, in ciascuna delle prime due mappe, la posizione dei pixel ricadenti in ogni zona, in modo da potermi dedicare all’individuazione dei colori delle zone stesse.

pixel_sicilia_zone_primo_giorno = {}
pixel_sicilia_zone_primo_giorno['A'] = [262,174]
pixel_sicilia_zone_primo_giorno['B'] = [182, 188]
pixel_sicilia_zone_primo_giorno['C'] = [105, 186]
pixel_sicilia_zone_primo_giorno['D'] = [106, 208]
pixel_sicilia_zone_primo_giorno['E'] = [170, 230]
pixel_sicilia_zone_primo_giorno['F'] = [219, 269]
pixel_sicilia_zone_primo_giorno['G'] = [248, 266]
pixel_sicilia_zone_primo_giorno['H'] = [222, 216]
pixel_sicilia_zone_primo_giorno['I'] = [246, 202]
pixel_sicilia_zone_secondo_giorno = {}
pixel_sicilia_zone_secondo_giorno['A'] = [520,174]
pixel_sicilia_zone_secondo_giorno['B'] = [438, 188]
pixel_sicilia_zone_secondo_giorno['C'] = [364, 186]
pixel_sicilia_zone_secondo_giorno['D'] = [364, 209]
pixel_sicilia_zone_secondo_giorno['E'] = [431, 230]
pixel_sicilia_zone_secondo_giorno['F'] = [477, 268]
pixel_sicilia_zone_secondo_giorno['G'] = [506, 265]
pixel_sicilia_zone_secondo_giorno['H'] = [480, 216]
pixel_sicilia_zone_secondo_giorno['I'] = [504, 202]
Utilizzando le librerie Pillow è possibile ottenere informazioni sui singoli pixel delle immagini.
image = Image.open(file_png)
pixel = image.getpixel(i, j)
La funzione getPixel(), passando in input la posizione di un pixel, restituisce un vettore contenente la triade delle componenti dei colori primari nella forma RGB (red, green, blue), grazie alla quale è possibile risalire al colore del pixel desiderato.
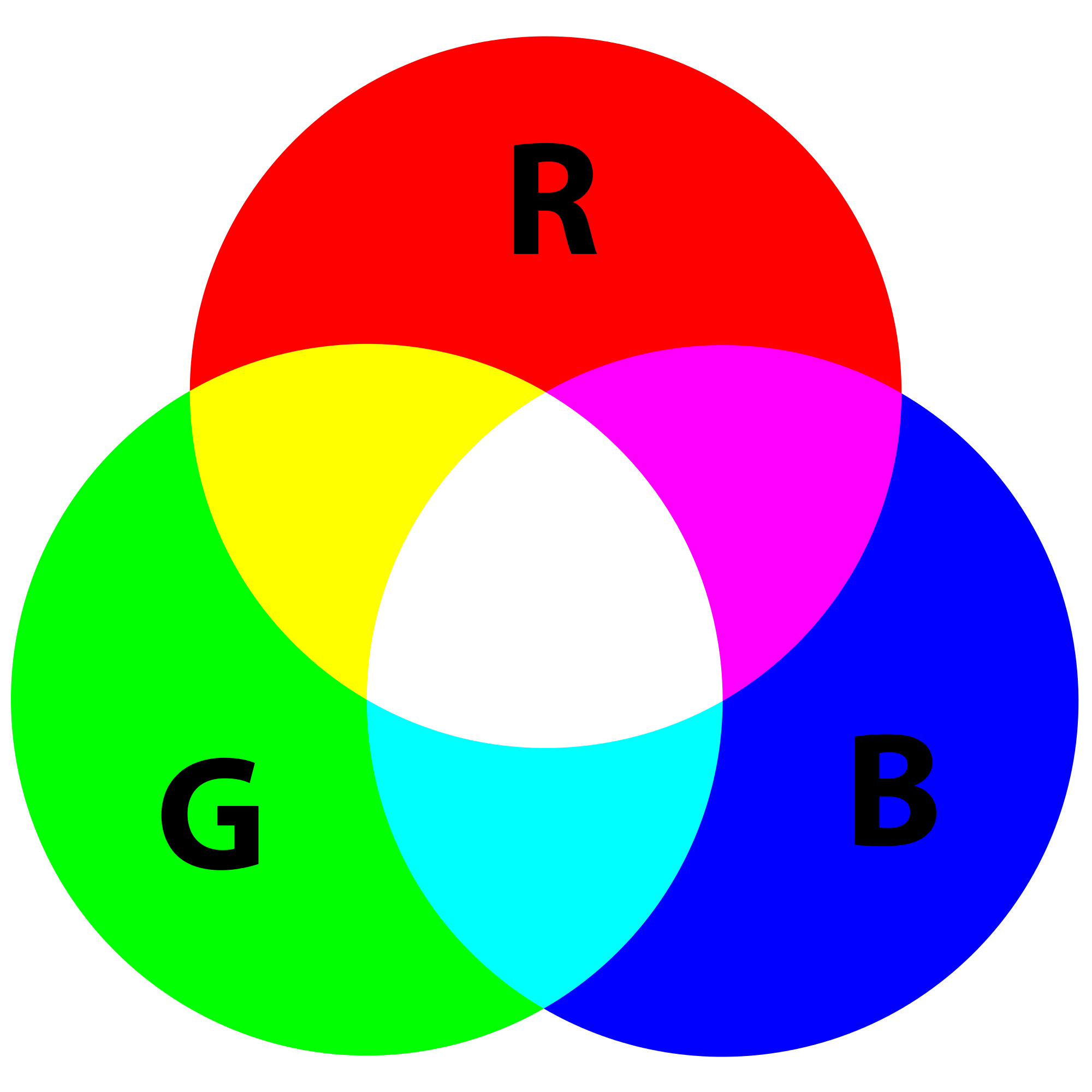
In base ai valori delle componenti di ciascun colore è possibile adesso ottenere il livello di allerta della zona interessata.
def get_allerta(r,g,b):
if r == 0 and g == 255 and b == 0:
return 'ALLERTA VERDE - GENERICA VIGILANZA'
elif r == 255 and g == 255 and b == 0:
return 'ALLERTA GIALLA - ATTENZIONE'
elif r == 255 and g == 204 and b == 0:
return 'ALLERTA ARANCIONE - PREALLARME'
elif r == 255 and g ==0 and b==0:
return 'ALLERTA ROSSA - ALLARME'
else:
return ''
Ad esempio, la triade (0,255,0), corrisponde al colore VERDE, la triade (255,0,0) corrisponde al colore ROSSO e così via.
Infine è stata definita una struttura adatta a contenere le informazioni estratte dal bollettino PDF; successivamente è stata salvata in un file JSON e pubblicata su un server raggiungibile via Web.
previsioni = {}
previsioni['fonte'] = 'Regione Siciliana - Dipartimento della Protezione Civile'
previsioni['allerta_meteo'] = {}
previsioni['allerta_meteo']['date'] = []
previsioni['allerta_meteo']['url'] = full_url.replace(' ', '%20')
prev = collections.OrderedDict()
prev[primo_giorno_text] = collections.OrderedDict()
prev[secondo_giorno_text] = collections.OrderedDict()
for zona in ['A','B','C','D','E','F','G','H','I']:
rgb = get_pixel(picture, pixel_sicilia_zone_primo_giorno[zona][0], pixel_sicilia_zone_primo_giorno[zona][1])
allerta = get_allerta(rgb[0], rgb[1], rgb[2])
prev[primo_giorno_text]['ZONA ' + zona]= allerta
for zona in ['A','B','C','D','E','F','G','H','I']:
rgb = get_pixel(picture, pixel_sicilia_zone_secondo_giorno[zona][0], pixel_sicilia_zone_secondo_giorno[zona][1])
allerta = get_allerta(rgb[0], rgb[1], rgb[2])
prev[secondo_giorno_text]['ZONA ' + zona]= allerta
previsioni['allerta_meteo']['date'] = prev
with open('allerta.json', 'w') as f:
json.dump(previsioni, f, ensure_ascii=False)
move_cmd = 'mv allerta.json ../../gpirrotta.tk/regione-siciliana/protezione-civile/allerta.json'
os.system(move_cmd)
Tale codice sorgente è stato quindi fatto eseguire una volta al giorno dai vigilantes del conte (che oggi chiameremmo cron) al fine di produrre il seguente output:
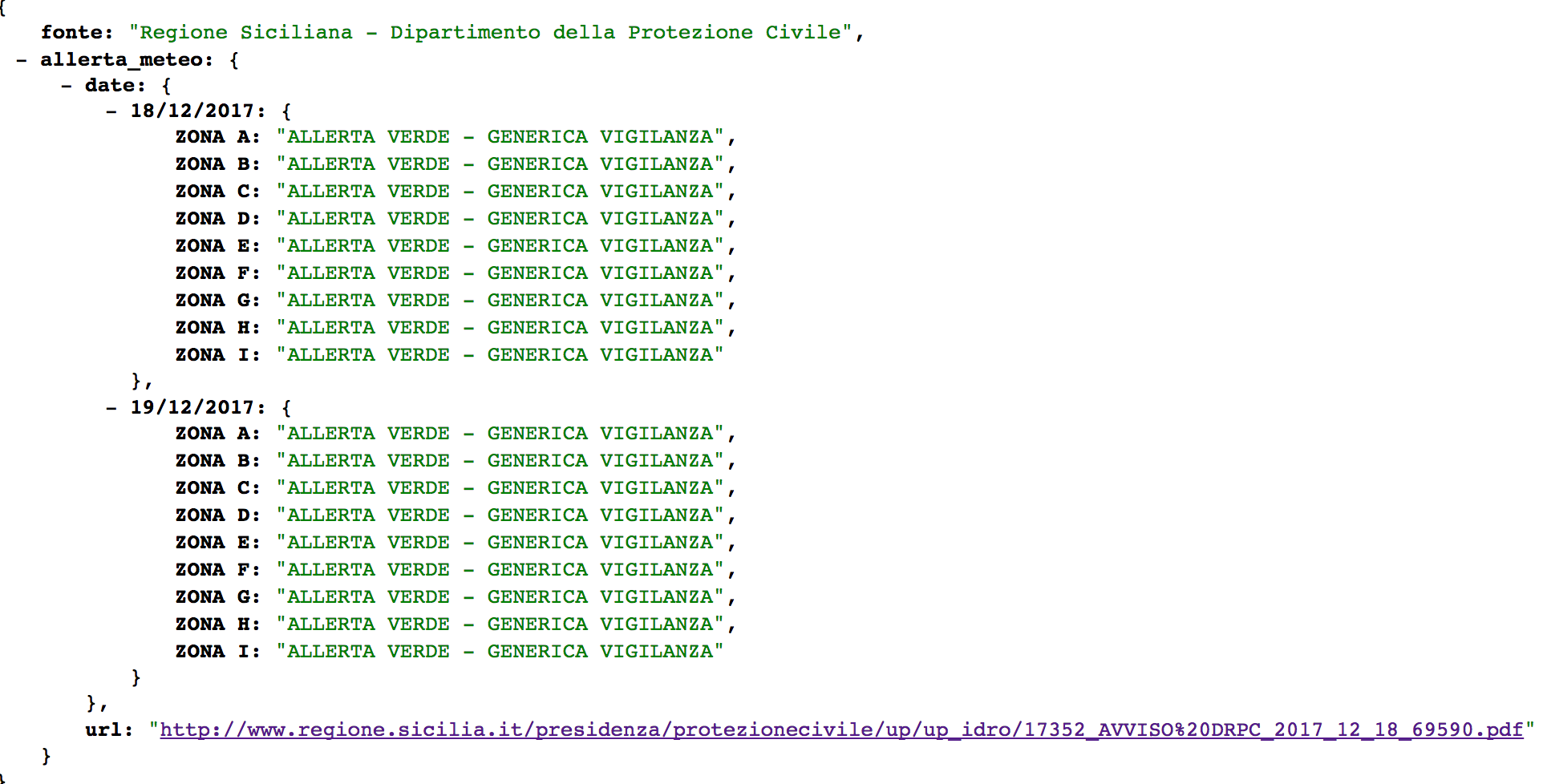
[…] E fu così che ritornar potei, a notti placide e soavi sogni, pensate un pò al signorotto piacque, questa mia idea di agir così com’io ho testè scritto…
E c’è chi dice di aver sentito il conte, adesso lui in preda ad incubi notturni, accennar sibilante insolite parole… xml…RSS…POP.
Nessuno seppe però mai cosa intendesse dire, tra veglie, convulsioni e tormenti, con quegli strani e indecifrabili farfugliamenti…
Ioan Pairot
P.S. Non so se in futuro il servizio rimarrà sempre attivo, ma se così sarà i posteri lo potranno trovare al seguente URL. E il codice sorgente qui.