While in the previous post I explained why XML alone is not sufficiently powerful in the Semantic Web context in this post I will explain how to overcome the XML semantic markup limitations.
#}
To solve the problem the W3C Consortium has formalized a conceptual layer called Resource Description Framework (RDF), which aims to provide an abstract formalism to describe resources. The RDF is a neutral domain/application metadata model which can be viewed as a directed labeled graph and provides a valid solution to the metadata representation problems on the Web. The RDF model ensures interoperability between applications exchanging machine–understandable information on the Web.
The first letter of RDF acronym stands for Resource but, what is a resource? A resource is every concrete or abstract thing identified by a URI and can be really anything: an image, a document, a person, a book, etc.
The URI, acronym of Uniform Resource Identifier, is instead a simple
string identifying uniquely a generic resource that can be an image,
a video, a service, anything, even not available online. If the resource
is located on the Web we call it Uniform Resource Locator (URL) where
the http protocol identifies the mechanism to access the resource. For
instance, the address Web http://giovanni.pirrotta.it represents the URL
of my blog. If the resource is identified
by a name belonging to a namespace we call it Uniform Resource
Name (URN). The URN is used when we have to identify a resource
without specifying a particular location but simply a membership in
a specific domain. For example, urn:isbn:12238789879 identifies a specific
resource within ISBN codes.
The URI syntax may change, but in general absolute URIs are written as follows:
<scheme>:<scheme-specific-part>
If a URI ends with the hash character (#), followed by a name, it is called qualified URI and it used to identify many resources in the same document.
Moreover we define as a property each attribute, characteristic or relation useful to describe a resource. To describe the domain of interest, a very important role is played by properties describing attributes and relations among resources. With properties we can specify everything about everything, and, since a property is also a resource, it is identified by a URI.
Now we can define the statement as the basic knowledge unit in RDF. It is composed by a subject, that is a resource, a predicate, which is the property, and is again a resource, and by an object, that can be a resource or a literal. A literal is simply a typed primitive value, such as string, integer, float, etc.
RDF only proposes an abstract model to represent the knowledge on the Web without specifying any technical mechanism to realize it. The best way to evidentiate this formalism is to represent the defined statement through the use of a directed labeled graph.
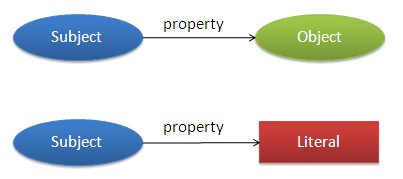
As we can see in the figure the subject is represented by an oval node, the predicate is represented by an arrow, and, if the object is a resource, it is represented by an oval node, whereas if the object is literal, by a rectangle.
Now I will explain how the RDF model works through an example.
Let us assume we want to define the following statement:
Martin Fowler is the author of the book "UML Distilled"
First of all we have to transform the statement in an RDF triple according to the following mapping:
- subject: we decide to identify the
UML Distilledbook with the http://example.org/umld URI; - predicate: we decide to identify the
is the author ofproperty with the http://example.org/hasAuthor URI; - object: we decide to identify the
Martin Fowlerperson with the “Martin Fowler string Literal.
We compose the following triple:
-> (http://example.org/umld, http://example.org/hasAuthor, “Martin Fowler”) <-
Note that RDF Model does not specify the way to represent the statements. We can use triples, graphs or whatever we retain useful for our purposes. For example, we can also think of the assertion as a simple relation
-> P(S) = O or P(S,O) <-
where P represents the property, S represents the subject and O represents the object.
Applying the above relation, we have
-> http://example.org/hasAuthor(http://example.org/umld) = “Martin Fowler” <-
The same statement can be represented as the graph shown in the next figure

The statement is formalized using the RDF model, but still nothing has been said about the type of resource defined. Now, all we know is that there is a resource with a property and a literal as a property value.
We know that the subject resource has a title and an ISBN code, and that also the object resource has a name and a surname. To correctly represent this extra information, the literal “Martin Fowler” must be transformed into a resource with a specific URI. In a similar way, as we have seen, it is possible to indefinitely extend the knowledge graph, thanks to the RDF model flexibility, simply adding nodes and arcs. As we can see in the figure, we replaced the literal with a new URI resource and we added new properties and relative literals values, better specifying the original statement.

RDF ensures a conceptual abstract model to define and use metadata; but to create and exchange them, a concrete syntax is necessary, and now XML comes into play.
Although, from a logical point of view, XML is not sufficiently powerful to describe Web resources, from a physical point of view, it proves to be an appropriate technology to serialize resources thanks to its rigorous syntax.
The following document represents the RDF/XML version of the previous statement
example:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/">
<rdf:Description about="http://example.org/umld">
<ex:hasAuthor>Martin Fowler</ex:hasAuthor>
</rdf:Description>
</rdf:RDF>
Inside an RDF/XML document, the rdf:RDF root node delimits the context within which all RDF statements are defined. In the rdf:RDF node, the text after the colon and before the equal, represents the namespace, namely an abbreviation we can use as a reference to uniquely identify the set of metadata we are using. The namespace mechanism does not only help us not to entirely rewrite the full URI when we refer to a resource, but also allows us to specify a set of names belonging to a specific domain, that defines an ontology.
Imagine we have to define the title property for a person and the
title property for a book. As we know, the property must be identified
by a URI and we cannot specify, within the same document, the title
property for both resources, since they have different meanings. To
overcome the problem, we can use namespaces to disambiguate meaning
differences between title properties, applying the right property
URI according to the context. Also, we can reuse namespaces defined
outside the RDF/XML document and accepted by the community as a
standard. That is the beauty of the RDF interoperability.
To describe an RDF statement, we must represent the triple subject,
predicate and object in the RDF/XML document. To define the subject,
we assign the subject URI to the rdf:about attribute of the rdf:Description
tag. Inside the rdf:Description tag we must specify all properties related
to the subject.
Considering Martin Fowler as a resource, we will have
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/">
<rdf:Description about="http://example.org/umld">
<ex:title>UML Distilled</ex:title>
<ex:isbn>0201325632</ex:isbn>
<ex:hasAuthor rdf:resource="http://example.org/mfowler"/>
</rdf:Description>
<rdf:Description about="http://example.org/mfowler">
<ex:firstname>Martin</ex:firstname>
<ex:lastname>Fowler</ex:lastname>
</rdf:Description>
</rdf:RDF>
As we can see from previous examples, we defined a new namespace,
called ex, within the rdf:RDF tag, in order to refer to RDF/XML
document resources in abbreviated form. With the same simplicity we
can import other namespaces in the same document to increase the
vocabularies available to describe resources.
In addition to the RDF/XML syntax, other triple-oriented RDF serializations exist, such as the N–Triples and Notation 3 (N3) formats.
N–Triples format is simply the assertion sequence where each statement is in the form
<subject><predicate><object>.
If we wanted to describe our previous resources in N–Triples format this would be the result:
<http://example.org/umld><http://example.org/hasAuthor><http://example/mfowler>.
<http://example.org/umld><http://example.org/title> "UML Distilled".
<http://example.org/umld><http://example.org/isbn> "0201325632".
<http://example.org/mfowler><http://example.org/firstname> "Martin".
<http://example.org/mfowler><http://example.org/lastname> "Fowler".
Also N3 format allows to describe resources using RDF model but, unlike the XML syntax, ensures a better human readibility. The same example in N3 format reads:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix ex: <http://example.org/>.
ex:umld ex:hasAuthor ex:mfowler;
ex:title "UML Distilled";
ex:isbn "0201325632".
ex:mfowler ex:firstname "Martin";
ex:lastname "Fowler".
That’s all for now.
In the next post I will focus the discussion on the RDF Schema Model (RDFs).
I will explain the way to create the vocabulary of resources in order to describe the meaning of classes and properties to help machines process data efficiently.
So stay tuned!