Suppose we want to become a policeman and to participate in the selection we need to complete the online request application available in the police Website. To do this, we decide to rely this task to our software agent to achieve an independent interaction between the software agent and the police homepage. Simplifying a lot, our software agent could start from the police homepage and, through string-matching analysis and exploration of the links, it might be able to recognize a page containing the words selection and 2013 and it could “think” to have found the right page to start its interaction.
Imagine we encounter the sentence
In 2013, the minimum required height for male candidate is 1.65
Obviously, a human being would have no trouble understanding in reading time the semantics of the sentence, because he is a being endowed with intelligence. For a man there are no problems to understand the difference between numbers 2013 and 1.65, the first indicating the year and the second the height.
But, how can you say this to the computer? Is the computer able to understand unambiguously the sentence, grasping all nuances? Of course, our software agent cannot automatically extract semantics from text since the only text itself is meaningless for machines. Then, how can we help our software to understand the text; what can we do to make it more intelligent?
The only way to help the computer to understand something is to rewrite the sentence in a structured way, using markers to define the meaning of parts.
For example, we can rewrite the previous sentence using the following markers:
[Start of requirements]
[A date] {In 2013}
[closely] {the minimum}
[it is not accessible without] {required}
[a measure] {height}
[a genre] {for male}
[those who want to access] {candidate}
[semantic link {height}] {is}
[limitation for access] {1.65}
[end of sentence] {.}
In this way, we specify each concept with a marker indicating the semantics and allowing a software agent to interpret the meaning of terms enclosed in braces automatically. Although our goal is to fill the request application for the police selection, we can easily see that the simple understanding of a sentence can be a difficult task for a non-human user. You can already guess now that the understanding of the text above mentioned in the labeled sentences depends on the ability of a software to know the meaning of the markers. Thus, the idea is to create markers, as terms of a vocabulary formally defined, powerful enough to set and share meaning by machines.
The future of the Web, according to Tim Berners-Lee vision, is to extend the actual Web into an environment where we can publish not only data, but also information describing the data, called metadata, which are essential to determine their meaning. We have to decorate pages with extra information to explain the meaning contained. To achieve this target we have to use a knowledge representation common model, shared by all people and sufficiently expressive.
All information will be expressed by formal descriptive statements saying the relationship existing between two resources (i.e. Michael is a student, the sky is blue, etc.) and data can be represented as a giant global graph, highly interconnected and finally machine-understandable.
The Semantic Web goal is to extend the actual Web, transforming it into the Web of Data. The semantic technologies provide necessary tools to reuse information implementing systems for typifying content and links between pages. The Semantic Web research area includes a set of evolving technologies, standards and tools forming a technological stack; each level represents the basis for the levels defined at higher levels as we can see in the Figure.
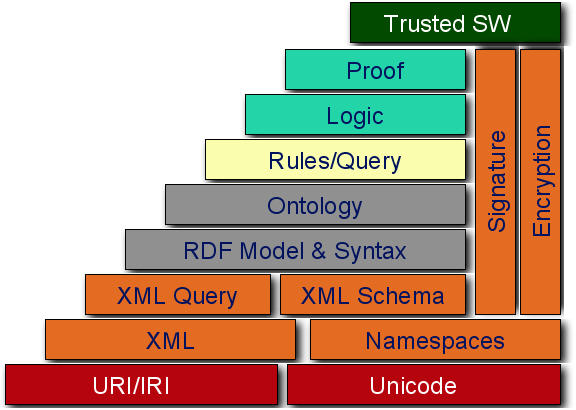
But, how do we represent the information written in HTML in a structured way? And how do we specify the meaning of each single abstract or concrete concept? The reply in next posts!
Stay tuned!